Reference¶
Annot workflow¶
This workflow representation gives an overview, how from a user point of view experiments with annot are annotated.
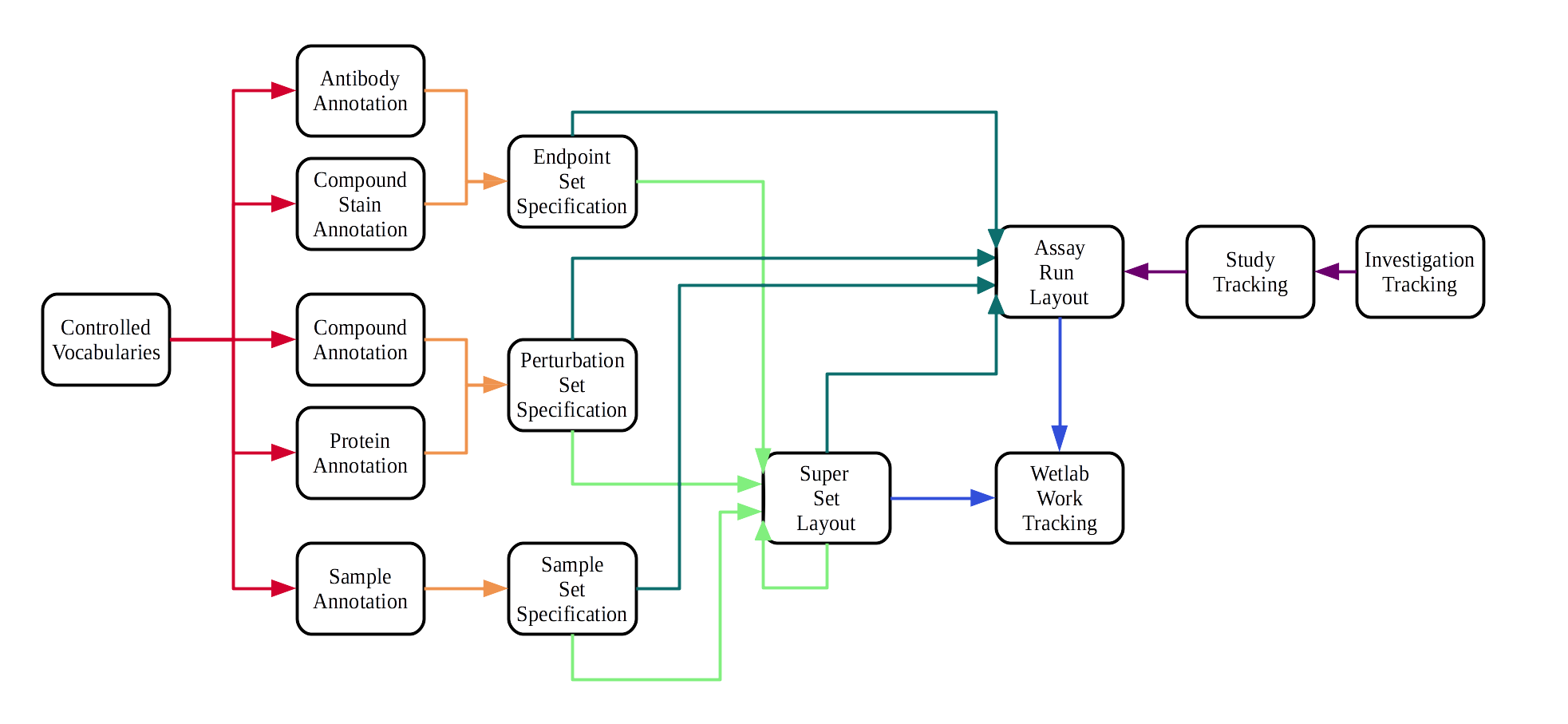 An! workflow
An! workflow
Assay reagents and samples are first annotated via the annot web interface or via Excel spreadsheet that can be uploaded into annot. This annotation step enforces the use of controlled vocabulary and official gene, protein, compound and cell line identifiers (red arrows). Annotated reagents and samples are next combined into endpoint, perturbation, and sample sets. In this step, additional experimental details can be specified, for example reagent concentrations, cell seeding density, or cell passage number (orange arrows).
For assays that involve robot pipetting, array spotting, or cyclic staining, super sets can be generated (light green arrows). Finally, for each assay run, endpoint, perturbation, sample and super sets are merged to a run specific assay layout (dark green arrows).
Assays and supersets that are regularly processes by the lab can be directly tracked in annot. There the exact data, protocol and the person who did the lab work can be specified (blue arrows). Lastly, assays can be grouped into studies and studies into investigations (purple arrows).
Docker and how the annot folder is structured¶
Annot is deployed within the docker distribution platform. In detail annot is packed into a docker-machine, where it is split into five docker containers:
 An! docker continer stack
An! docker continer stack
- annot_nginxdev_1 or anno_nginx_1 contains the web server.
- annot_db_1 contains the database engine.
- annot_dbdata_1 contains the data stored in the database.
- annot_webdev_1 or annot_web_1 contains the actual annot code base.
- annot_fsdata_1 contains all stored non-database data.
These five containers can be built and spun up together utilizing docker-compose command either with the dcdev.yml file for the development version or the dcusr.yml file for the production version.
In addition, these five containers define the main folder structure found in the annot folder.
- nginx contains construction information for the annot_nginx_1 container.
- nginxdev contains construction information for the annot_nginxdev_1 container.
- dbdata contains construction information for the annot_dbdata_1 container.
- web contains the actual annot code base and construction information for the annot_web_1 container.
- webdev contains construction information for the annot_webdev_1 container.
- fsdata contains construction information for the annot_fsdata_1 container.
For the annot_db_1 container is taken care in the dcdev.yml and dcusr.yml and the pgsql.env. all those file are found straight in the annot folder itself.
There is an additional folder - man - which contains the rst restructured text and md markdown files for this very user manual. The sphinx documentation generator tool can be used to generate the final documentation out of this files.
Further there is the LICENSE and a README.md file.
The nginx and nginxdev folder¶
Nginx and gunicorn serve as annot’s web server backbone. Gunicorn figures thereby as unix WSGI (web server gate way interface) HTTP server. Nginx figures as HTTP proxy server.
The nginxdev and nginx folder contains a:
- Dockerfile, which contains the container building instruction for annot_nginxdev_1 and annot_nginx_1. This containers are constructed out of the official nginx docker image.
- annotnginxdev.conf or annotnginx.conf file which contains the particluar nginx configuration.
Gunicorn is called from the dcdev.yml or dcusr.yml file. The gunicorn library is listed in the requiremnet.txt in webdev and wev folder.
The dbdata folder¶
PostgreSQL and the psycopg2 library serve as annot’s database backbone. PostgreSQL figures thereby as database engine, psycopg2 figures as python postgresql database adapter.
The dbdata folder contains a:
- Dockerfile with the container building instruction for annot_dbdata_1. This container is constructed out of the official postgresql docker image.
The building instruction for annot_db_1 container (which contains the postgesql datbase engine) are part of the dcdev.yml and dcusr.yml file. The postgresql engine related configuration settings are stored in the pgsql.env file in the annot folder. This container is constructed out of the official postgresql docker image. The psycopg2 library is listed in the requiremnet.txt in webdev and web folder.
Splitting database engine and data into two containers (annot_db_1 and annot_dbdata_1 makes it really easy to update the database engine without loosing the data stored in the database.
The web, webdev and fsdata folder¶
The webdev and web folder contain a:
- Dockerfile with the container building instruction for annot_webdev_1 and annot_web_1. These containers are constructed out of the official debian based python3 docker image.
- requirement.txt file which lists the addition python libraries needed in the annot project.
The fsdata folder contains a
- Dockerfile with the container building instruction for annot_fsdata_1. This container is constructed out of the official debian docker image.
Splitting the annot code base (annot_webdev_1 or annot_web_1) and filesystem part where files are stored (annot_fsdata_1) into separate containers makes it easy to update the annot code base without losing the data files stored on the filesystem.
Python3¶
Annot is written in the python3 language. For running Annot and especially for assay layouting you should at least be a bit familiar with this language.
acJson - the assay coordinate json file format¶
Annot’s assay layout backbone is the acpipe_acjson library. Acpipe_acjson is a python3 library to handle the acjson file format, a file format developed to log complicated biological wet lab experiment layouts. Acjson file format complies fully withe the json standard.
Django¶
Annot is django based web application. Django as such is a python based web framework. Annot makes use of the django, django-admin - which is leveraged as annot’s GUI (graphical user interface), and the external django-selectable library - which provides searchable dropdown list boxes to the django-admin based GUI. Particularly the lookups.py files found in several django apps are part of the django-selectable implementation.
If you not yet are familiar with djano and django-admin, then it’s maybe a good idea to work through the tutorial from the official django documentation.
The folder structure inside the annot/web/ folder¶
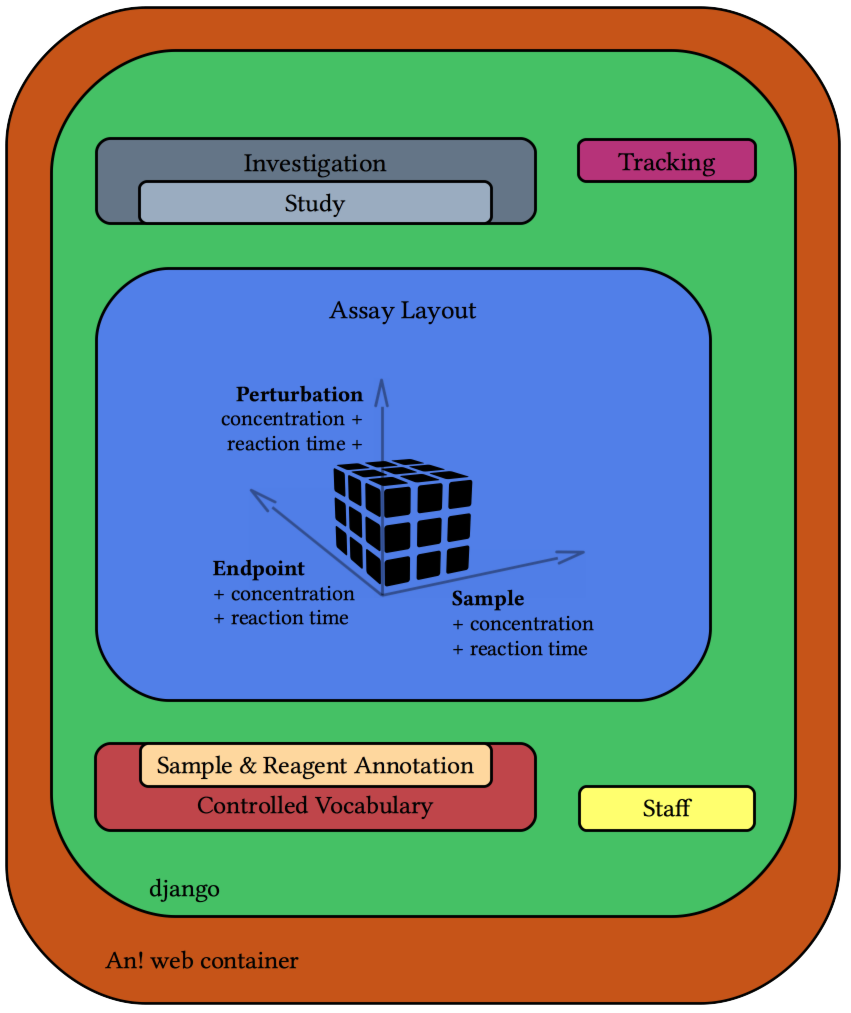 An! django stack
An! django stack
The annot/web folder contains the actual annot code base. The django main project folder (prjannot) and all django app folders (app*) can be found here. The whole project is structured as following:
- prjannot: main project folder
- appon0investigation: investigation annotation app
- app1study: study annotation app
- app2tack: app for date tracking specific supersets or assay. this app have to be adjusted to the lab specific needs or can be commented out in the prjannot/settings.py file if not needed.
- app3runset: acjson based assay layout annotation app
- app4superset: acjson based superset layout annotation app
- appacaxis: acjson based sample, perturbation and endpoint layout annotation app
- appbrreagent*: annotation brick app for detailed reagent annotation.
- appbrsample*: annotation brick app detailed sample annotation.
- appbrxperson: app to store a list of scientist (staff) involved in the experiments logged by annot.
- appon*: controlled vocabulary app, one for each ontology.
- appsabrick: sample and reagent brick system administration app.
- appsavocabulary: controlled vocabulary system administration app.
- apptool: this app some command line and annot commands implemented for our lab specific need. this code can be adapted to the own lab specific needs, or the whole app can be commented out in the prjannot/settings.py file in not needed.
- nix: backup and maintenance related unix shell script and cron job code.
The man folder¶
The man folder contains this very documentation.
Documentation is mainly written in markdown, deployed via read the docs and generated using sphinx. Annot must be under your PYTHONPATH, to be able to be processable by sphinx.
If you would like to contribute on the manual, please read at least read the doc’s getting started, get familiar with the basic of markdown, and check out Daniele Procida’s “what nobody tells you about documentation” talk.